| Navigation Menu
|

|
| General issues of Vaccine
|
|
|
| General issues of Tropical med.
|
|
|
| General issues of Travel med.
|
|
|
| Trematode (fluke, distoma)
|
|
|

Disease frequency measurement
Bradford Hill Criteria for assuming causality
|
|
In terms of the association between exposure and outcome,
exposure is more likely to be causal if ....
|
| 1. Strength of association
|
the stronger the association is.
|
| 2. Consistency
|
in the more varieties settings the association is observed.
|
| 3. Specificity
|
the more specific the exposure is, i.e., the exposure is associated with only single outcome.
|
| 4. Temporality
|
the exposure comes first and the outcome appears after the exposure
|
| 5. Biological gradient
|
the more (or less) exposure is associated with more frequent outcome (exposure dose dependent).
|
| 6. Plausibility
|
the mechanism between the exposure and the outcome can be explained according to biological body of knowledge.
|
| 7. Coherence
|
the mechanism between the exposure and the outcome can be proven by certain medical testings.
|
| 8. Experiment
|
some intervention to the exposure can change frequency and/or extent of the outcome.
|
| 9. Analogy
|
another similar exposure is associated with another similar outcome.
|
Classification of Bias
Catalogue of Bias
| Major classification
|
Specific name
|
Description
|
Affecting design
|
| Selection bias
|
Sample is not properly representative of population
|
Ascertainment bias
|
Inappropriate definition of population
|
Any observational design
|
| Healthy worker effect
|
Current employees are more likely to be healthy than general population and ex-employees
|
Cohort, esp. historical
|
| Detection bias
|
Diagnostic procedures are different between case and control
|
Case-control
|
Attrition bias
(Loss to follow-up)
|
needless to explain
|
Cohort
Clinical trial
|
| Non-response bias
|
a.k.a. Healthy volunteer effect; Voluntary participants are not representative of population
|
Any observational design
|
| Language bias
|
Medical articles written in languages unfamiliar to researchers are more likely to be ignored
|
Meta-analysis
Systematic review
|
| Publication bias
|
Researches with negative results are more likely to be unpublished
|
Meta-analysis
Systematic review
|
Information bias
(Measurement bias)
|
Observation is not properly conducted
|
Non-differential misclassification bias
|
Failure to properly measure exposure/outcome and inappropriate allocations of groups in the same weight for both
- underestimate effect size (decrease power)
|
Any design
|
| Differential misclassification bias
|
Failure to properly measure exposure/outcome and inappropriate allocations of groups in different weights in-between
- under- or overestimate effect size
|
Any design
|
- └Recall bias
|
- └(subcategory of differential misclassification)
Participants are more likely to recall their memory in skewed way according to their outcome status
|
Any design
|
- └Reporting bias
|
- └(subcategory of differential misclassification)
Participants are more (or less) likely to report their exposure according to their outcome status
|
Any design
|
| Observer/interviewer bias
|
Observers/interviewers are more likely to observe/draw interviews toward exposure according to case outcome status
|
Any design
|
| Ecological fallacy
|
|
Ecological design
|
| Regression to the mean
|
Extreme observations in initial investigations will be toward true population value in later investigations
|
Cohort
Clinical trial
|
| Hawthorne effect
|
Observation itself can affect outcome
|
Clinical trial
|
| Lead-time bias
|
Screening trial can diagnose outcome even in its earlier latent period which fallaciously show longer survival
|
Screening trial
|
| Confounding
|
Third factors affect both of exposure and outcome
|
Confounding may occur even in RCT if randomization process is inappropriate (as systematic error) or randomly allocated groups are heterogenous by chance (as random error)
|
Difference between Population and Sample
Accuracy=Validity and Precision=Reliability
Definition
| Accuracy |
Validity
|
- Closeness of observed values to true population values
|
| Precision |
Reliability
|
- Closeness of observed values to each other among sample
|

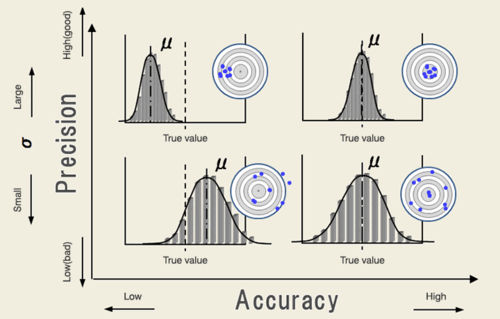
Accuracy in
[math]\displaystyle{ x }[/math]-axis, Precision in
[math]\displaystyle{ y }[/math]-axis
*In this example, μ is sample mean, not the population mean
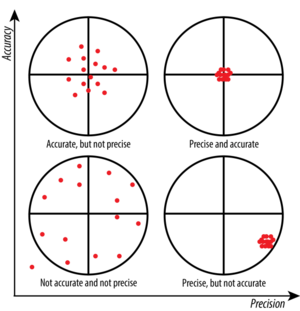
Precision in
[math]\displaystyle{ x }[/math]-axis, Accuracy in
[math]\displaystyle{ y }[/math]-axis
Tips in Case-control design
Sampling (selection bias)
| Case sampling
|
Control sampling
|
- Incident case
- for outcome with short duration or poor survival
- Prevalent case
- for rare or chronic outcome
|
- The same inclusion criteria as case
- except for outcome itself
|
- Population-based case
- from surveillance, registry, death certificates, etc.
- easy to define population
|
- Population-based control
- random sampling from the same population
- random-digit dialing, population registry, etc.
- For occupation-based case, beware of healthy worker effect and select control from similar occupation with the same exposure as the population
|
- Hospital-based case
- from hospital
- difficult to define population
|
- Hospital-based control
- sampling from the same hospital
- must be exposed at the same extent as the population
|
- Population-based control
- Only when assumable that all patients from the population visit the hospital and patients from other than population never visit the hospital
|
- Matching increases precision of observations, i.e. increases power
- Matching does not decrease bias
- Matching masks the effect of matching variables themselves
- Overmatching makes extents of exposure of both groups too similar, which leads to decrease power
- Matching with age and sex only is a better way
- 1:n matching (n>1) increases power
- 1:4 is maximum; more matching brings no more benefit
|
Measurement (Information bias)
| Observer bias
|
- To mask case/control status to observers
|
| Recall bias
|
- To use memory aids
- To mask research question/hypothesis to participants
|
Confounding and Effect modification
Sampling
Simple random sampling (SRS)
Standard Error with Finite Population Correction in SRS
The formula [math]\displaystyle{ SE = \frac{\sigma}{\sqrt{N}} }[/math] assume that samples are selected from infinite population with replacement (allowing repetitive sampling of the same individuals).
In reality, sampling is made from finite population without replacement (not allowing repetitive sampling of the same individuals).
When sampling from finite population without replacement, if fraction [math]\displaystyle{ \frac{n}{N} }[/math] > 5% (0.05), [math]\displaystyle{ SE }[/math] will be too large.
Repeating sampling from finite population of size of [math]\displaystyle{ N }[/math] by sample size of [math]\displaystyle{ n_i }[/math] decreases population size at every sampling:
population size at [math]\displaystyle{ m }[/math]th sampling = [math]\displaystyle{ N - \sum_{i=1}^m {n_i} }[/math]
If the fraction [math]\displaystyle{ \frac{n}{N} }[/math] > 5% (0.05), [math]\displaystyle{ SE }[/math] should be corrected by Finite Population Correction.
| Standard Error corrected by Finite Population Correction when [math]\displaystyle{ \frac{n}{N} }[/math] > 5% (0.05)
|
| [math]\displaystyle{ Finite\ Population\ Correction\ (FPC) = \sqrt{\frac{N-n}{N-1}} }[/math]
|
| [math]\displaystyle{ Corrected\ SE = FPC \times SE = \sqrt{\frac{N-n}{N-1}} \cdot \frac{\sigma}{\sqrt{N}} }[/math]
|
Two-stage (multi-stage) sampling
In case of two-stage sampling:
- Randomly sample primary sampling units (PSUs) (clusters) with probability proportional to size (PPS)
- larger size of PSUs (clusters) are more likely to be selected
- Randomly sample second-stage units (SSUs) (individuals) with the same number of individuals within PSUs (clusters)
- individuals in smaller size of PSUs are more likely to be selected
- final individual probability to be sampled is equivalent in entire population because of balancing probabilities between PSUs and SSUs
Stratified random sampling
To increase precision of estimates in heterogeneous groups in sample, separated (stratified) random sampling from each group in population can be chosen.
In stratified random sampling, sampling fractions in strata can be varied, e.g., sample size of minority groups can be larger than majority groups.

